|
Henry (Yuhao) Zhou
I am currently pursuing entrepreneurial endeavors after finishing the Facebook (now
Meta)
AI Residency
program.
I worked with Dr. Michael Auli and Alexei Baevski on
unsupervised speech pretraining.
During my undergraduate studies at
University of Toronto,
my focuses are machine learning, software engineering and system control.
Since January in 2017, I have been working as an undergraduate research assistant under
the supervision
of
Prof. Sanja Fidler and
Prof. Jimmy Ba
on computer vison and reinforcement learning projects.
Before I worked as a research assistant, I primarily spent my time on various software
engineering
internships.
During which period, I gained strong coding skills through in-depth experience on
large-scale
engineering projects.
|

|
|
Address:
410-37 Grosvenor St
Toronto, ON Canada. M4Y 3G5
|
Email:
henryzhou @ cs.toronto.edu
henry dot zhou @mail.utoronto.ca
|
CV /
LinkedIn /
GitHub /
Google
Scholar
|
Research
I am broadly interested in machine learning, deep learning and its application in
computer vision,
natural language processing, speech, and locomotion control.
(* Denotes equal contribution.)
|
|
A Comparison of Discrete Latent Variable Models for Speech Representation
Learning
Henry Zhou, Alexei Baevski, Michael Auli
arxiv, 2020
Abstract /
Bibtex /
Arxiv /
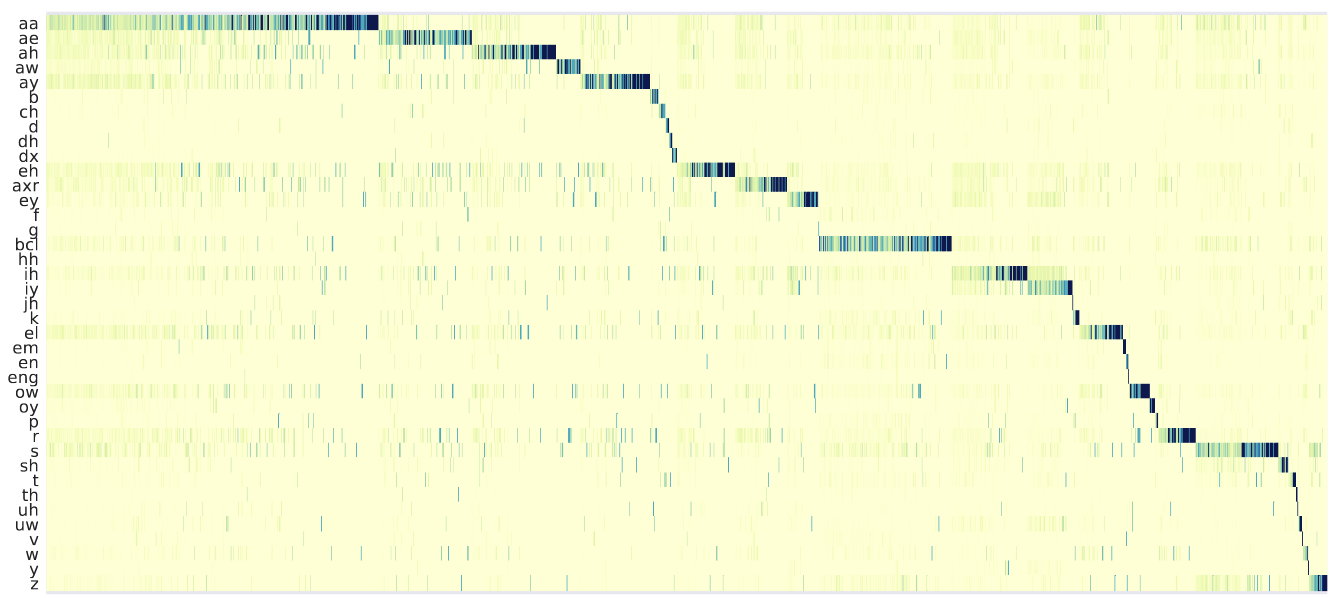
Neural latent variable models enable the discovery of interesting structure in speech
audio data. This
paper presents a comparison of two different approaches which are broadly based on
predicting future
time-steps or auto-encoding the input signal. Our study compares the representations
learned by vq-vae
and vq-wav2vec in terms of sub-word unit discovery and phoneme recognition performance.
Results show
that future time-step prediction with vq-wav2vec achieves better performance. The best
system achieves
an error rate of 13.22 on the ZeroSpeech 2019 ABX phoneme discrimination challenge.
@misc{https://doi.org/10.48550/arxiv.2010.14230,
doi = {10.48550/ARXIV.2010.14230},
url = {https://arxiv.org/abs/2010.14230},
author = {Zhou, Henry and Baevski, Alexei and Auli, Michael},
keywords = {Audio and Speech Processing (eess.AS), Artificial Intelligence (cs.AI),
Machine Learning
(cs.LG), Sound (cs.SD), FOS: Electrical engineering, electronic engineering, information
engineering,
FOS: Electrical engineering, electronic engineering, information engineering, FOS:
Computer and
information sciences, FOS: Computer and information sciences},
title = {A Comparison of Discrete Latent Variable Models for Speech Representation
Learning},
publisher = {arXiv},
year = {2020},
copyright = {arXiv.org perpetual, non-exclusive license}
}
}
|
|
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech
Representations
Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
arxiv, 2020
Abstract /
Bibtex /
Arxiv /
Facebook
Blog /
Hugging Face /
Yann
Lecun's Tweet
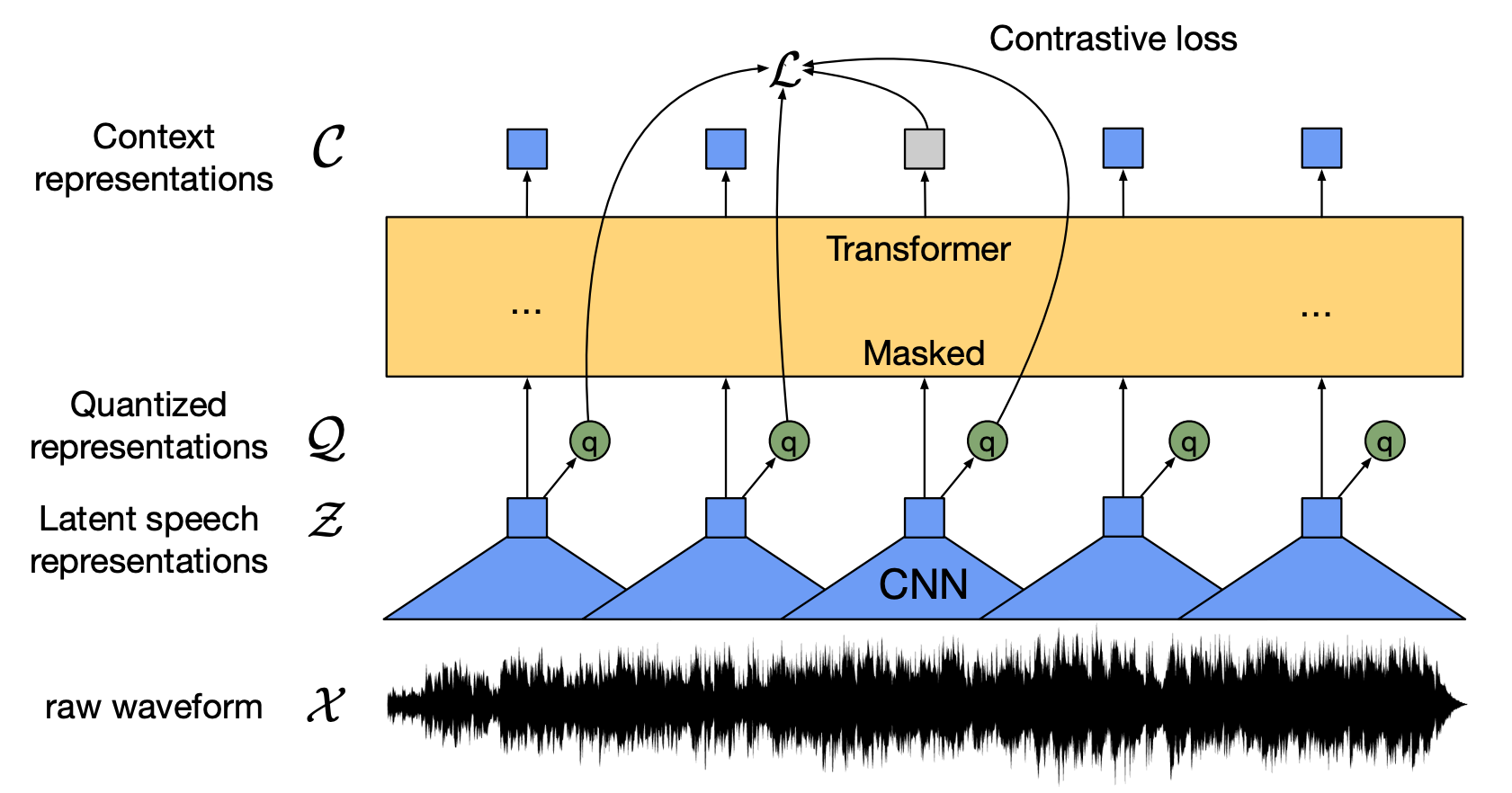
We show for the first time that learning powerful representations from speech audio
alone followed by
fine-tuning on transcribed speech can outperform the best semi-supervised methods while
being
conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves
a contrastive
task defined over a quantization of the latent representations which are jointly
learned. We set a new
state of the art on both the 100 hour subset of Librispeech as well as on TIMIT phoneme
recognition.
When lowering the amount of labeled data to one hour, our model outperforms the previous
state of the
art on the 100 hour subset while using 100 times less labeled data. Using just ten
minutes of labeled
data and pre-training on 53k hours of unlabeled data still achieves 5.7/10.1 WER on the
noisy/clean test
sets of Librispeech. This demonstrates the feasibility of speech recognition with
limited amounts of
labeled data. Fine-tuning on all of Librispeech achieves 1.9/3.5 WER using a simple
baseline model
architecture. We will release code and models.
@misc{baevski2020wav2vec,
title={wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations},
author={Alexei Baevski and Henry Zhou and Abdelrahman Mohamed and Michael Auli},
year={2020},
eprint={2006.11477},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
|
|
Learning to Simulate Dynamic Environments with GameGAN
Seung Wook Kim, Yuhao Zhou, Jonah Philion, Antonio Torralba, Sanja
Fidler
Computer Vision and Pattern Recognition (CVPR), 2020
Abstract /
Bibtex /
Project Web /
Live Demos
Media:
Nvidia Twitter
/
Blog
Post /
YouTube
Explained /
Two Minute Papers /
GTA Adaptation on YouTube /
Vecture
Beat Blog
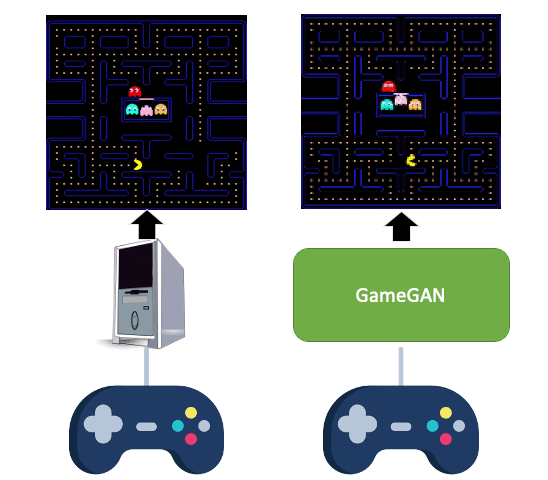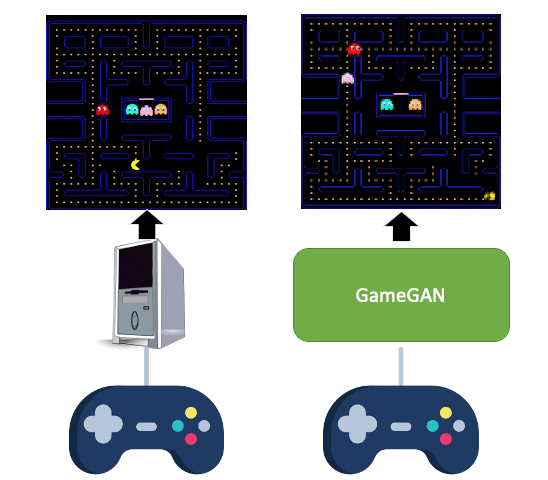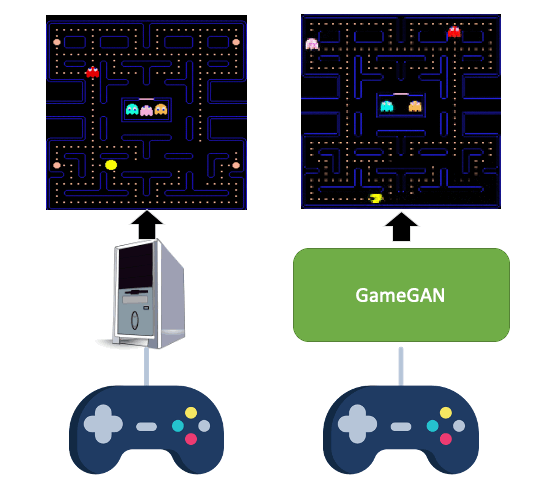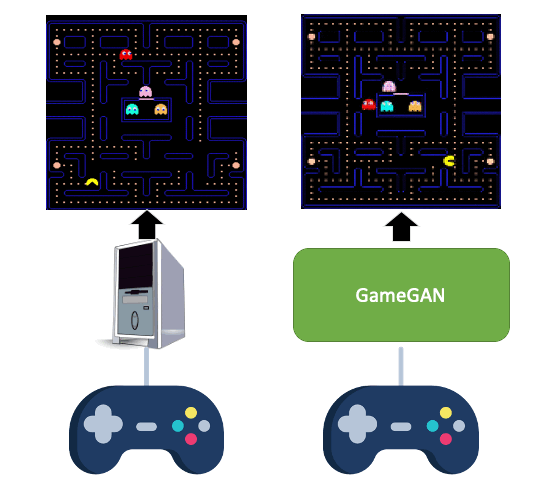
Simulation is a crucial component of any robotic system. In order to simulate correctly,
we need to
write complex rules of the environment: how dynamic agents behave, and how the actions
of each of the
agents affect the behavior of others. In this paper, we aim to learn a simulator by
simply watching an
agent interact with an environment. We focus on graphics games as a proxy of the real
environment. We
introduce GameGAN, a generative model that learns to visually imitate a desired game by
ingesting
screenplay and keyboard actions during training. Given a key pressed by the agent,
GameGAN "renders" the
next screen using a carefully designed generative adversarial network. Our approach
offers key
advantages over existing work: we design a memory module that builds an internal map of
the environment,
allowing for the agent to return to previously visited locations with high visual
consistency. In
addition, GameGAN is able to disentangle static and dynamic components within an image
making the
behavior of the model more interpretable, and relevant for downstream tasks that require
explicit
reasoning over dynamic elements. This enables many interesting applications such as
swapping different
components of the game to build new games that do not exist. We implement our approach
as a web
application enabling human players to now play Pacman and its generated variations with
our GameGAN.
@inproceedings{Kim2020_GameGan,
author = {Seung Wook Kim and Yuhao Zhou and Jonah Philion and Antonio Torralba and Sanja
Fidler},
title = {{Learning to Simulate Dynamic Environments with GameGAN}},
year = {2020},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {Jun.}, doi = {}}
|
|
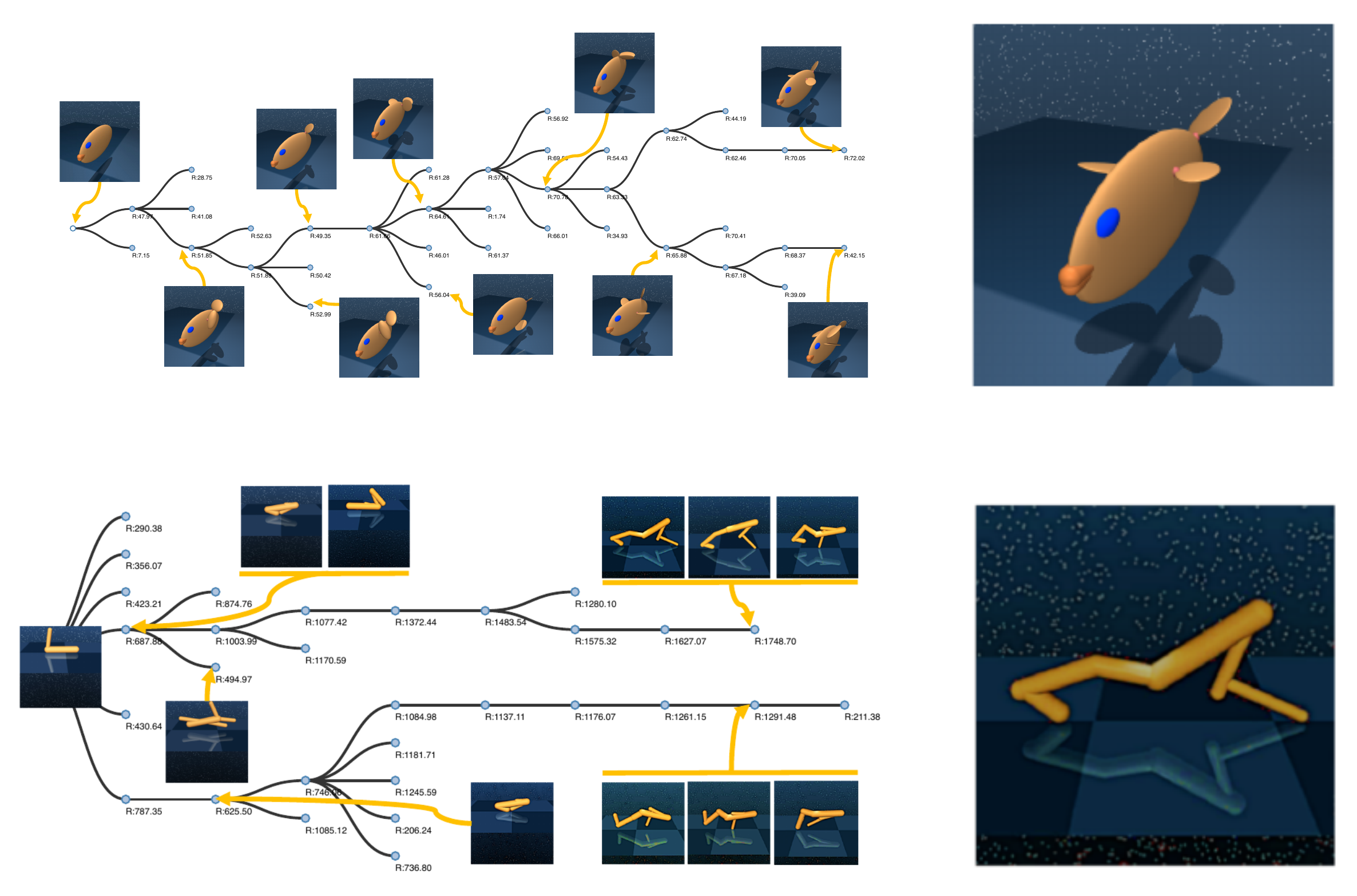
Neural Graph Evolution: Automatic Robot Design
Yuhao Zhou*, Tingwu Wang*, Sanja Fidler, Jimmy Ba
International Conference on Learning Representations, 2019
Abstract /
Bibtex /
Open Review /
Codes /
Project Web /
YouTube demo
Despite the recent successes in robotic locomotion control, the design of robot relies
heavily on human
engineering.
Automatic robot design has been a long studied subject, but the recent progress has been
slowed due to
the large combinatorial search space and the difficulty in evaluating the found
candidates.
To address the two challenges, we formulate automatic robot design as a graph search
problem and perform
evolution search in graph space.
We propose Neural Graph Evolution (NGE), which performs selection on current candidates
and evolves new
ones iteratively.
Different from previous approaches, NGE uses graph neural networks to parameterize the
control policies,
which reduces evaluation cost on new candidates with the help of skill transfer from
previously
evaluated designs.
In addition, NGE applies Graph Mutation with Uncertainty (GM-UC) by incorporating model
uncertainty,
which reduces the search space by balancing exploration and exploitation.
We show that NGE significantly outperforms previous methods by an order of magnitude.
As shown in experiments, NGE is the first algorithm that can automatically discover
kinematically
preferred robotic graph structures, such as a fish with two symmetrical flat side-fins
and a tail, or a
cheetah with athletic front and back legs.
Instead of using thousands of cores for weeks, NGE efficiently solves searching problem
within a day on
a single 64 CPU-core Amazon EC2.
@inproceedings{
wang2018neural,
title={Neural Graph Evolution: Automatic Robot Design},
author={Tingwu Wang and Yuhao Zhou and Sanja Fidler and Jimmy Ba},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=BkgWHnR5tm},
}
|
|
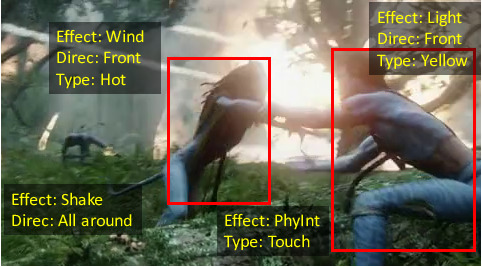
Now You Shake Me: Towards Automatic 4D Cinema
Yuhao Zhou, Makarand Tapaswi, Sanja Fidler
Computer Vision and Pattern Recognition (CVPR), 2018
(Spotlight)
Abstract /
Bibtex /
Project Web /
PDF /
CVPR
Spotlight /
Poster
Media:
UofT News /
CBC Radio
News /
Inquisitr
News
We are interested in enabling automatic 4D cinema by parsing physical and special
effects from untrimmed
movies.
These include effects such as physical interactions, water splashing, light, and
shaking, and are
grounded to either a character in the scene or the camera.
We collect a new dataset referred to as the Movie4D dataset which annotates over 9K
effects in 63
movies.
We propose a Conditional Random Field model atop a neural network that brings together
visual and audio
information, as well as semantics in the form of person tracks. Our model further
exploits correlations
of effects between different characters in the clip as well as across movie threads.
We propose effect detection and classification as two tasks, and present results along
with ablation
studies on our dataset, paving the way towards 4D cinema in everyone's homes.
@inproceedings{Zhou2017_Movie4D,
author = {Yuhao Zhou and Makarand Tapaswi and Sanja Fidler},
title = {{Now You Shake Me: Towards Automatic 4D Cinema}},
year = {2018},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {Jun.}, doi = {}}
|
|
Industry Experience
Please email me for more details of the experience.
|

|
Ello
Chief Speech Scientist
San Francisco, California
March, 2023 - Now
Empowering every child to max potential.
Leading the speech team on developing the speech recognition system, from research to production.
|
 |
Talka AI
Co-founder & Lead Architect
Toronto, ON
May, 2021 - February, 2023
A lot of different roles as in start-ups : )
Leading the ML and engineering team on developing novel solutions for business needs.
Participated in fund-raising, hiring, and management.
|
 |
Facebook AI Research
AI Resident
Menlo Park, CA
August, 2019 - August, 2020
AI research team. Natural Language Processing and Speech Team.
Worked with Michael Auli and Alexei Baevski on unsupervised speech pretraining
algorithms.
|
 |
Nvidia Corporation
Research Intern
Toronto, Canada
January, 2019 - July, 2019
AI research team.
Under the supervison of Prof. Sanja Fidler and Prof. Antonio Torralba, working on
Computer Vision
projects.
Research project on Generative Adversarial Networks (GAN) and Game Simulation.
|
 |
Intel PSG
PEY (Professional Experience Year) Intern
San Jose, CA
May, 2017 - December, 2017
Participated in software development in Quartus high-level synthesis group.
Engaged in large-scale C++ programming projects on software backward compatibility.
Enhanced customers' usability to use pre-compiled products to compile on latest Quartus
software. (Perl)
|
 |
Oracle Corp.
R&D Intern
Beijing, China
June, 2015 - Aug, 2015
Worked in R&D department cloud computing group.
Exposure to cloud-computing architecture and networking.
Utilized integrated tools to manage cloud-computing resources and services for the
entire R&D
department.
|
|
Projects
Some side/course projects I participated.
|

|
Towards a Practical sEMG Gesture Recognition System
Sebastian Kmiec*, Yuhao Zhou*
Supervisor: Stark Draper
University of Toronto 4th-year Capstone Project, 2019
John Senders Award (1 Team across all engineering disciplines' designs)
Selected as Distinction (Top 5% among the entire student groups).
Abstract /
UofT
News /
Mid-term Presentation /
Poster /
Final Report
Documentation /
In this project, we designed a real-time gesture recognition system for the purposes of
transradial
prostheses control.
Our system makes a step towards accessible prosthesis, with hardware that is both easy
to install and
inexpensive.
The focus of our project was to collect data from two Myo armband devices, and provide
highly accurate
and timely gesture prediction, from a large set of predefined gestures.
The midterm presentation updates the supervisor and project manager with progress.
The link to the slides are available here.
To avoid potential plagiarism, the final report of the project is available upon
requests.
Thank you for the understanding.
|
|
Academic Service
I am a reviewer for: IJCAI, NeurIPS, ICLR, ICASSP, ICML
|
|
